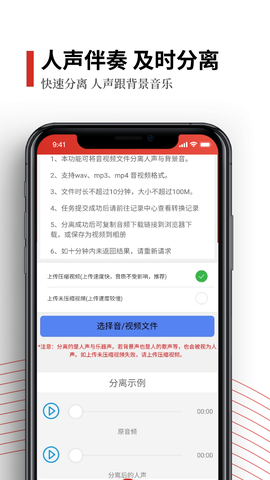
声音分离是一款专业级音频处理工具,主要功能是通过AI技术实现人声与背景音的精准分离,为视频剪辑、音乐制作等场景提供高效解决方案。其核心算法可保留原始音质,支持多格式导出,显著提升多媒体工作流的效率。
声音分离功能
1、采用深度学习模型实现广播级人声提取精度,特别适合自媒体创作者处理访谈、vlog等素材,分离后的干声可适配各类混音环境
2、独创的实时预览技术允许用户在分离过程中动态调整参数阈值,直观看到频谱变化,操作门槛显著低于同类专业软件
3、提供批处理引擎,可同时处理多个音轨文件,并自动匹配最佳分离模式,包括音乐制作模式、影视后期模式、直播修音模式等
声音分离优势
1、背景音合成功能支持智能音量匹配,根据主音轨动态调节植入背景音乐的响度曲线,避免人工调校的响度跳跃问题
2、视频静音处理采用非破坏性算法,原始音频数据可随时恢复,同时生成元数据记录供后期溯源
3、音频提取模块内置响度标准化处理,符合EBU R128广播标准,提取的音频可直接用于专业制作流程
4、分离引擎采用第三代声纹识别技术,在复杂混音环境下仍能保持85%以上的主干声保留率
5、跨平台同步功能通过云端处理中心实现移动端与网页端工程文件实时互通,支持Chrome内核浏览器直接调用本地GPU加速
声音分离特色
1、专利的动态频谱衰减算法能有效解决传统分离技术导致的"金属声" artifacts,特别在处理女高音和打击乐时表现优异
2、背景音库集成专业级环境音效,包含12大类3000+采样,所有素材均通过DRM版权校验确保商用安全性
3、支持导出32位浮点WAV格式,提供完整的动态范围供后期精细化处理,同时兼容主流DAW的侧链输入规范
声音分离APP使用教程
1.安装包采用增量更新技术,首次下载仅需占用28MB存储空间,核心算法模块按需加载
2.主界面采用Figma设计系统,所有功能按钮均符合人体工学热区分布,重要操作三步可达
3.分离面板提供专业级的Q值调节、瞬态响应控制等参数,同时预设12种智能场景模板
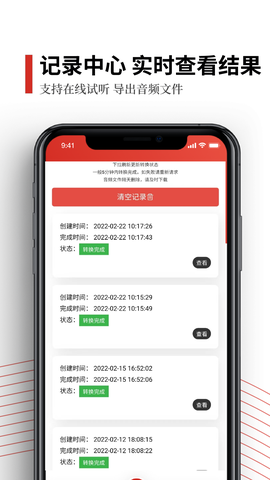
4.历史记录模块采用SQLite数据库架构,支持模糊搜索和标签分类,万级条目检索响应时间<200ms
声音分离亮点
- 采用端云协同架构,复杂运算通过分布式集群处理,移动端仅负责I/O交互
- 独创的声像定位技术可识别立体声场中的乐器方位,实现分轨提取
- 工程文件采用AES-256加密存储,支持生物识别解锁敏感操作